
 案例1-爬取开源中国的开源资讯
案例1-爬取开源中国的开源资讯
特别赞助 by:



# 介绍
为了演示Hutool-http的http请求功能,因此这个栗子用红薯家的开源资讯开刀,在此做个简单的Demo。
# 开始
# 分析页面
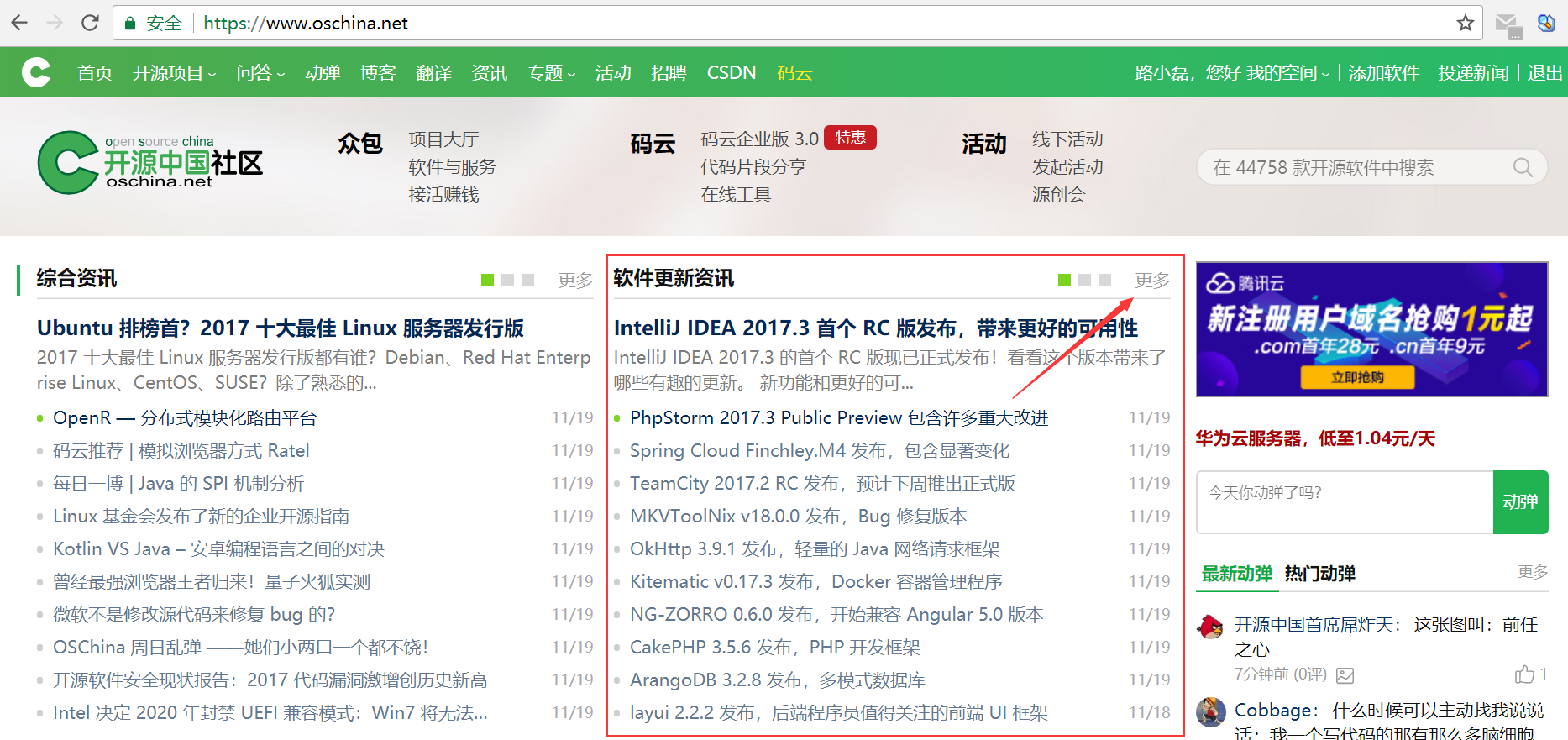
- 打开红薯家的主页,我们找到最显眼的开源资讯模块,然后点击“更多”,打开“开源资讯”板块。
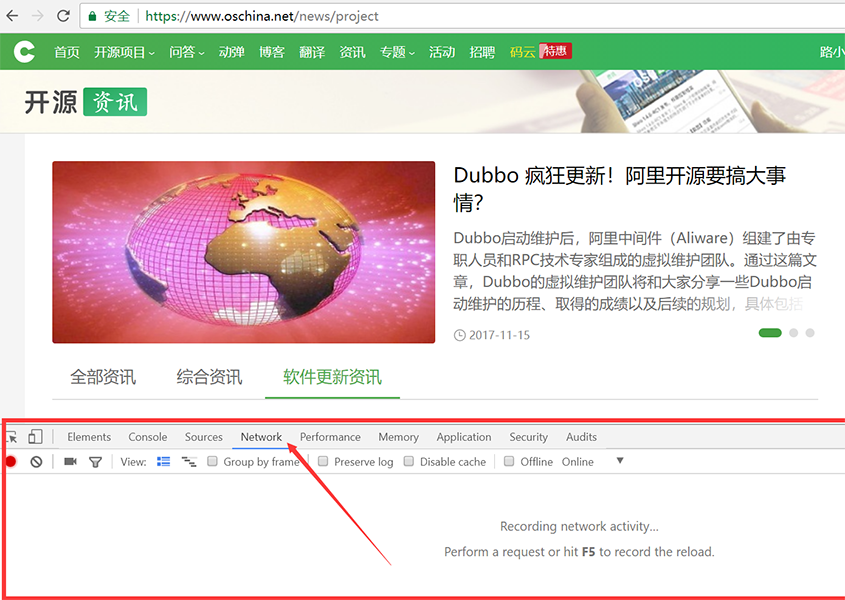
- 打开F12调试器,点击快捷键F12打开Chrome的调试器,点击“Network”选项卡,然后在页面上点击“全部资讯”。
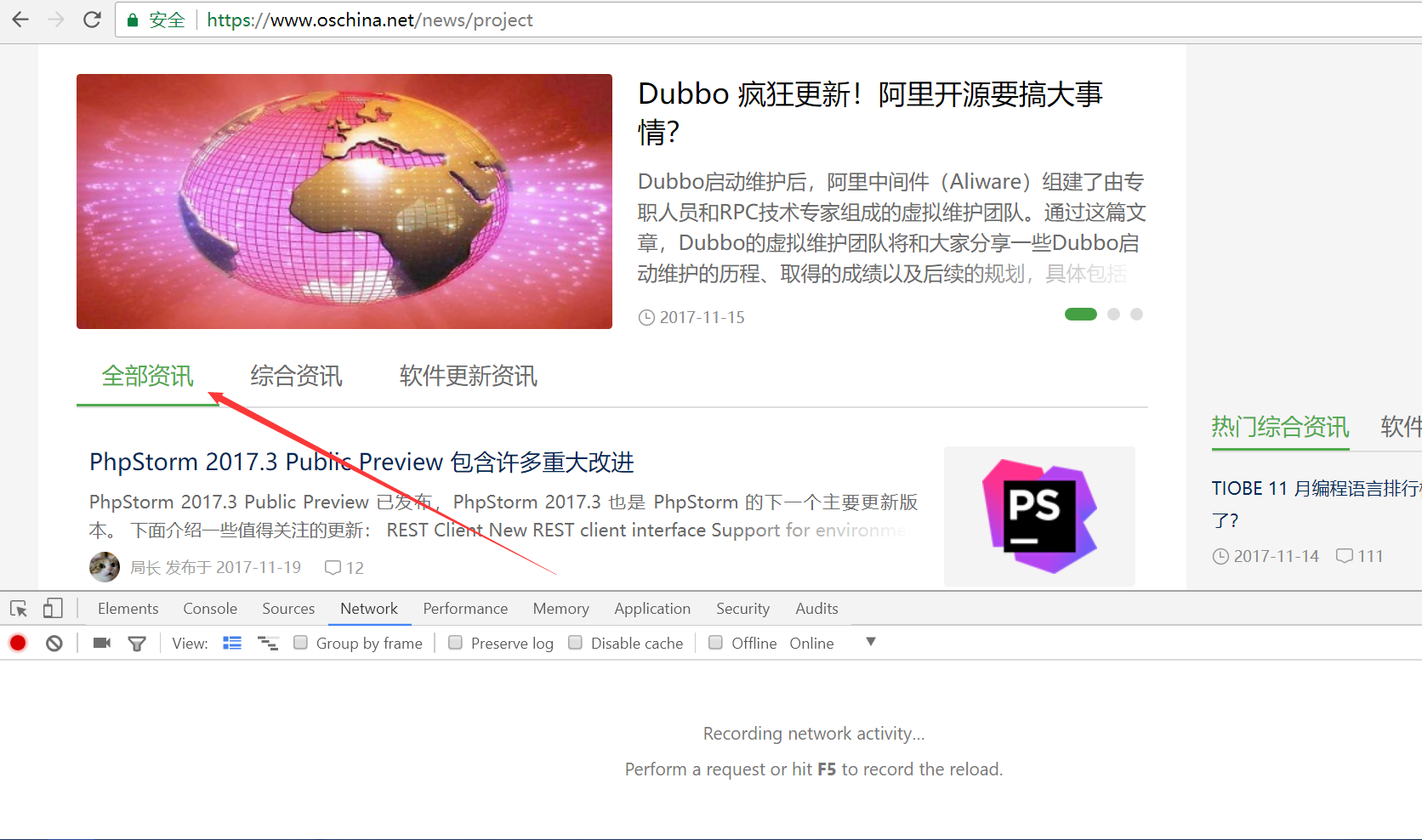
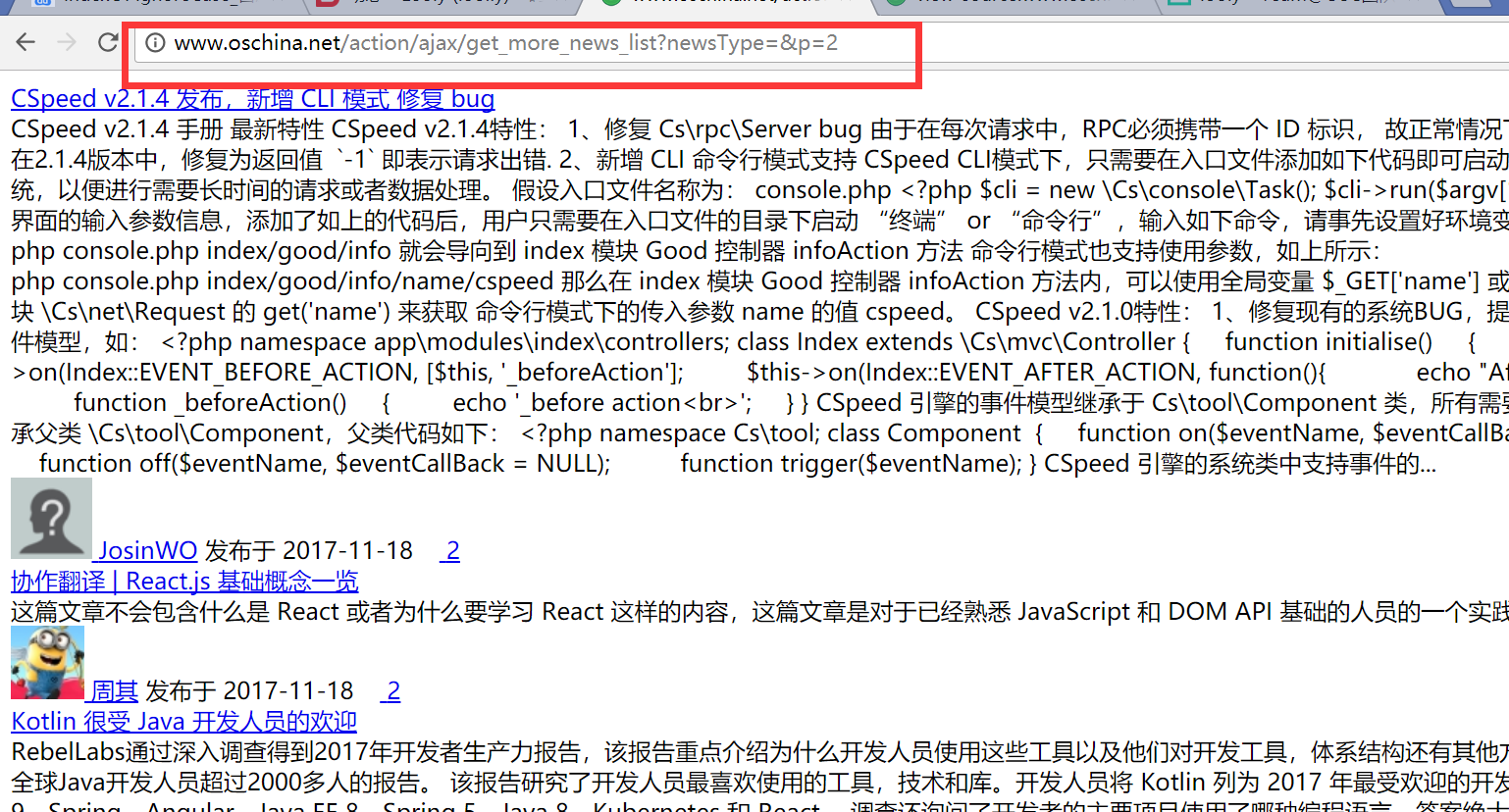
- 由于红薯家的列表页是通过下拉翻页的,因此下拉到底部会触发第二页的加载,此时我们下拉到底部,然后观察调试器中是否有新的请求出现。如图,我们发现第二个请求是列表页的第二页。
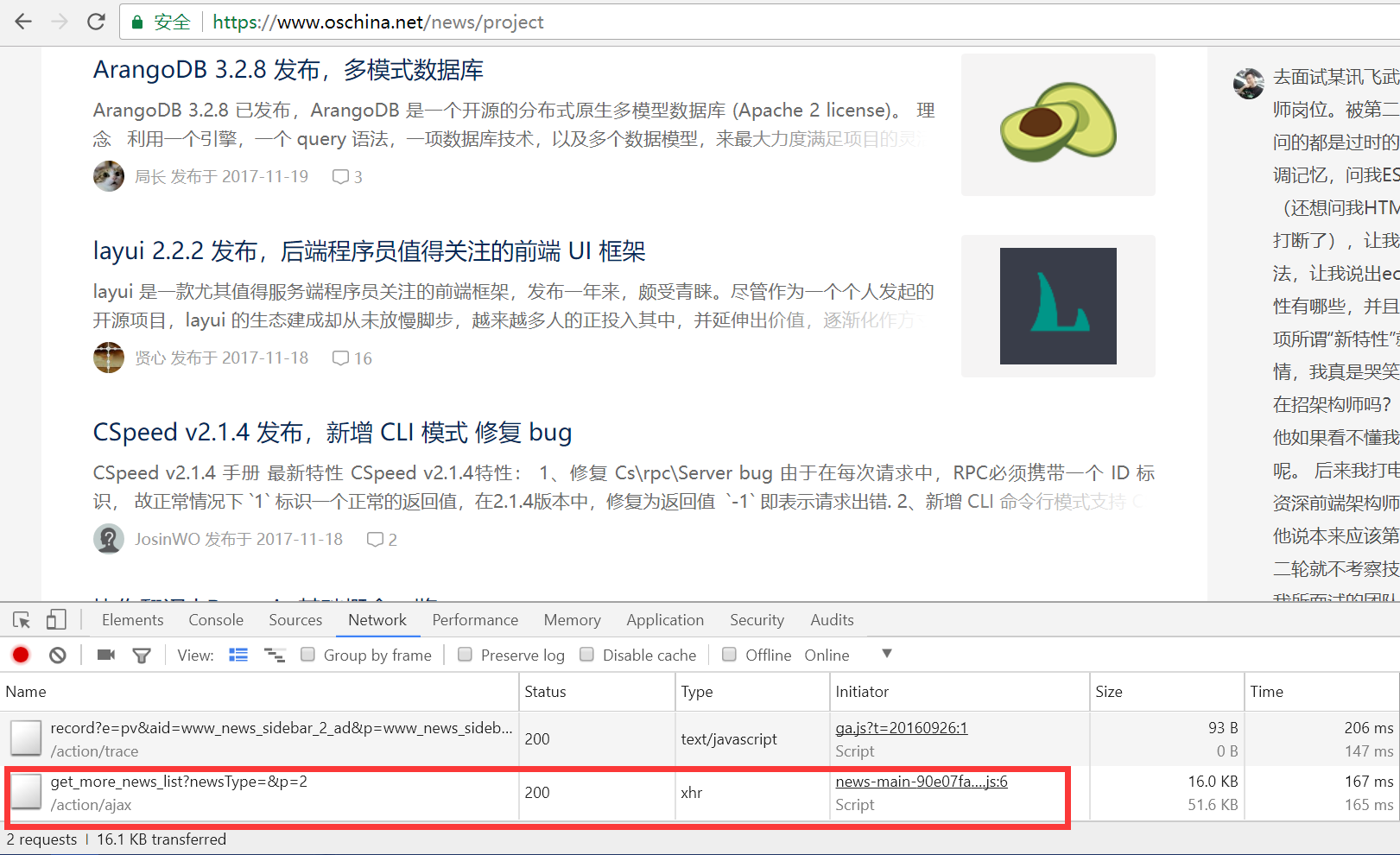
- 我们打开这个请求地址,可以看到纯纯的内容。红框所指地址为第二页的内容,很明显p参数代表了页码page。
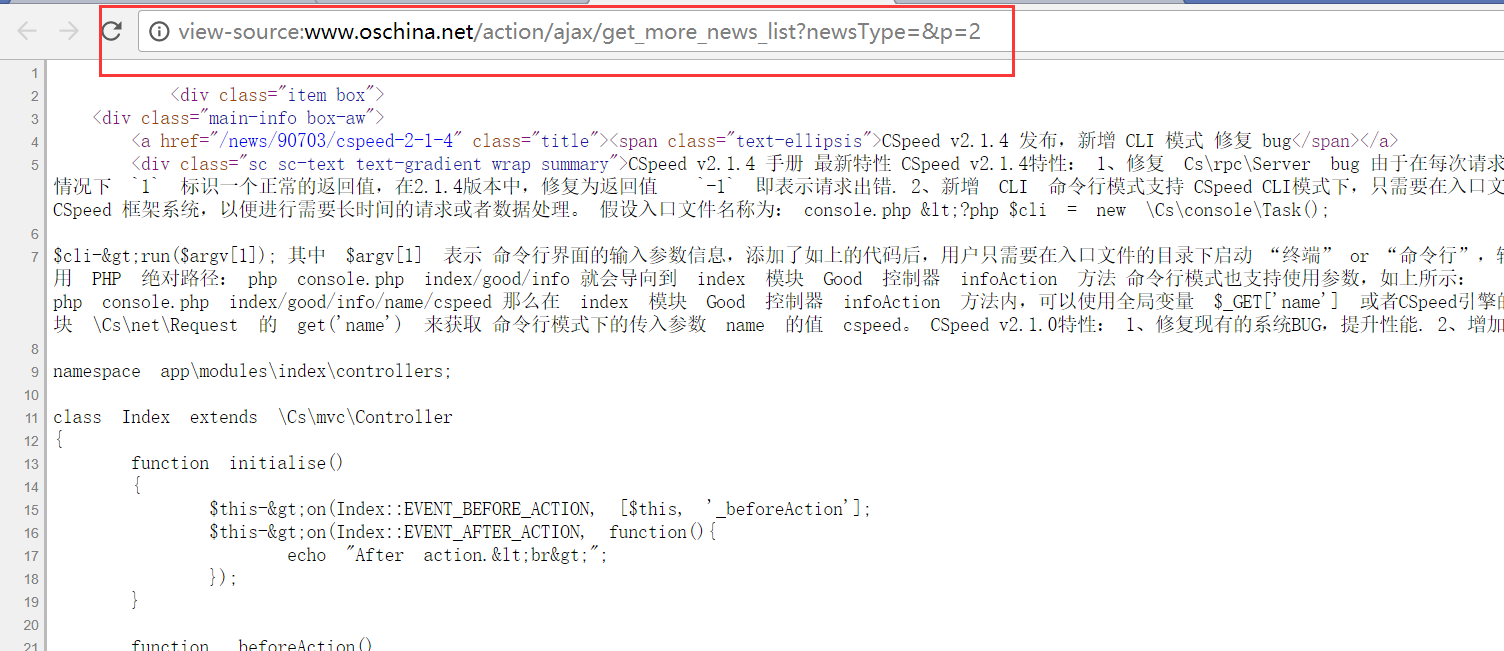
- 我们右键点击后查看源码,可以看到源码。
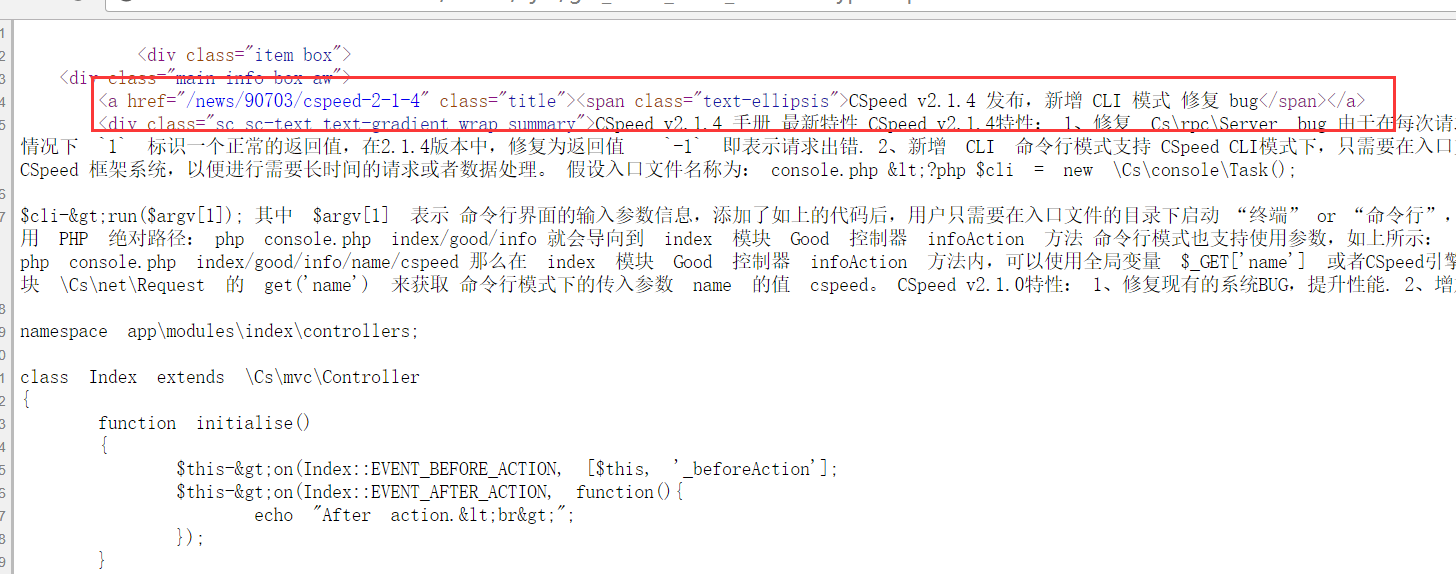
- 找到标题部分的HTML源码,然后搜索这个包围标题的HTML部分,看是否可以定位标题。
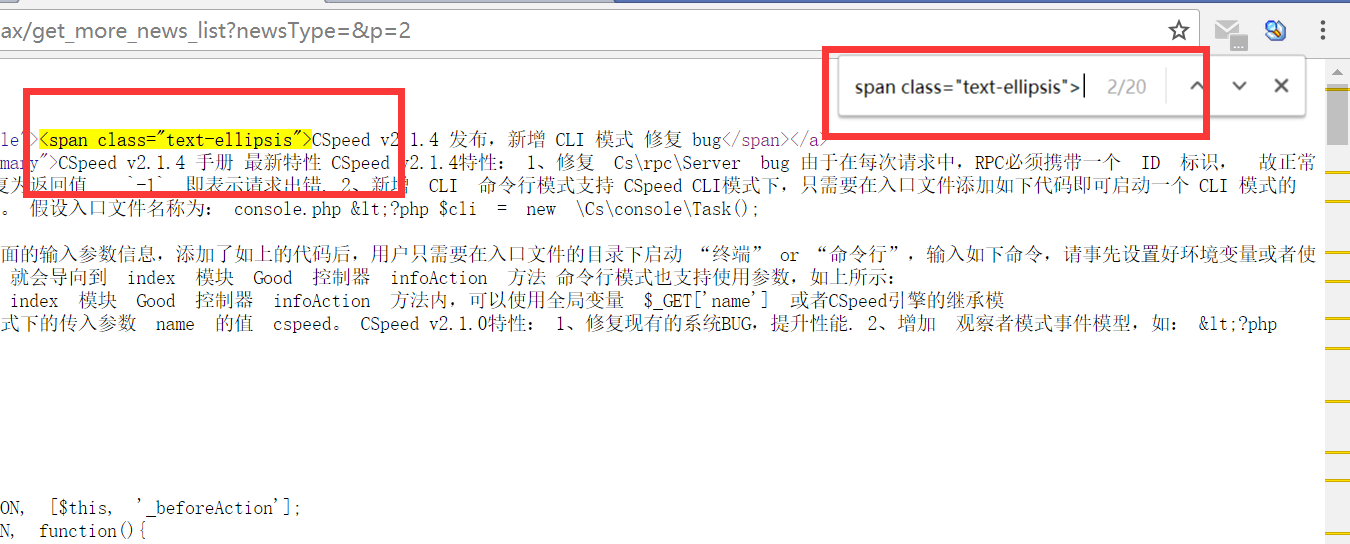
至此分析完毕,我们拿到了列表页的地址,也拿到了可以定位标题的相关字符(在后面用正则提取标题用),就可以开始使用Hutool编码了。
# 模拟Http请求爬取页面
使用Hutool-http配合ReUtil请求并提取页面内容非常简单,代码如下:
//请求列表页
String listContent = HttpUtil.get("https://www.oschina.net/action/ajax/get_more_news_list?newsType=&p=2");
//使用正则获取所有标题
List<String> titles = ReUtil.findAll("<span class=\"text-ellipsis\">(.*?)</span>", listContent, 1);
for (String title : titles) {
//打印标题
Console.log(title);
}
抓取结果为:
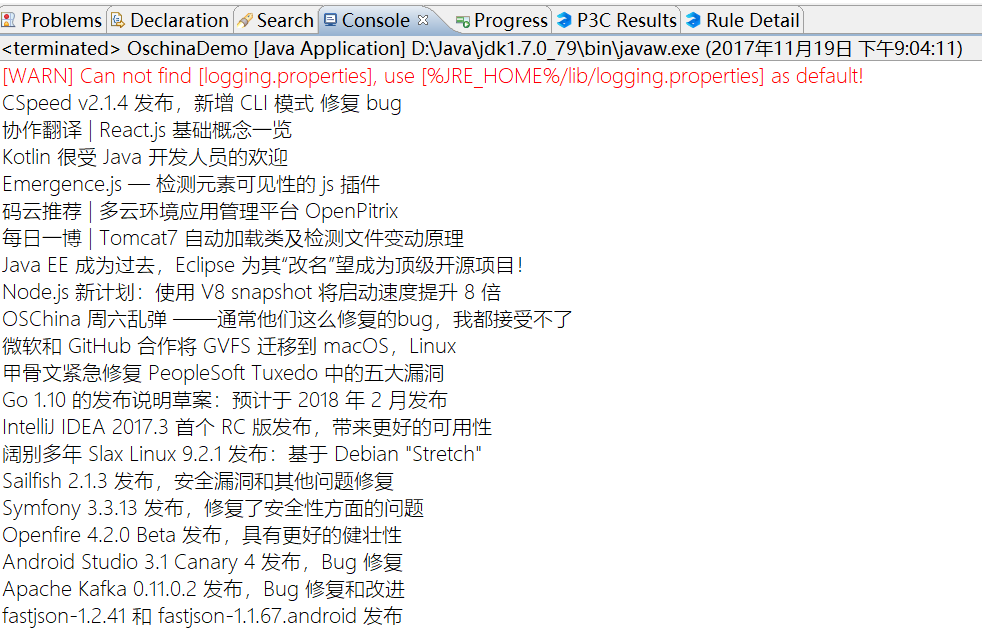
其实核心就前两行代码,第一行请求页面内容,第二行正则定位所有标题行并提取标题部分。
这里我解释下正则部分:ReUtil.findAll方法用于查找所有匹配正则表达式的内容部分,第二个参数1表示提取第一个括号(分组)中的内容,0表示提取所有正则匹配到的内容。这个方法可以看下core模块中ReUtil章节了解详情。
<span class=\"text-ellipsis\">(.*?)</span>这个正则就是我们上面分析页面源码后得到的正则,其中(.*?)表示我们需要的内容,.表示任意字符,*表示0个或多个,?表示最短匹配,整个正则的意思就是。,以<span class=\"text-ellipsis\">开头,</span>结尾的中间所有字符,中间的字符要达到最短。?的作用其实就是将范围限制到最小,不然</span>很可能匹配到后面去了。
关于正则表达式这块可以看下我的博客:正则表达式简明参考 (opens new window)
# 结语
不得不说,抓取本身并不困难,尤其配合Hutool会让这项工作变得更加简单快速,而其中的难点便是分析页面和定位我们需要的内容。
真正的内容抓取分为四个部分:
- 找到列表页(很多网站都没有一个总的列表页)
- 请求列表页,获取详情页地址
- 请求详情页并使用正则匹配我们需要的内容
- 入库或将内容保存为文件
而且在抓取过程中我们也会遇到各种问题,包括但不限于:
- 封IP
- 对请求Header有特殊要求
- 对Cookie有特殊要求
- 验证码
这些问题都有一些解决办法,具体要在具体的开发中分析解决。
希望大家看到这个栗子有所启发,也为Hutool提供更多更好的意见~
上次更新: 2025/06/11, 11:31:35

